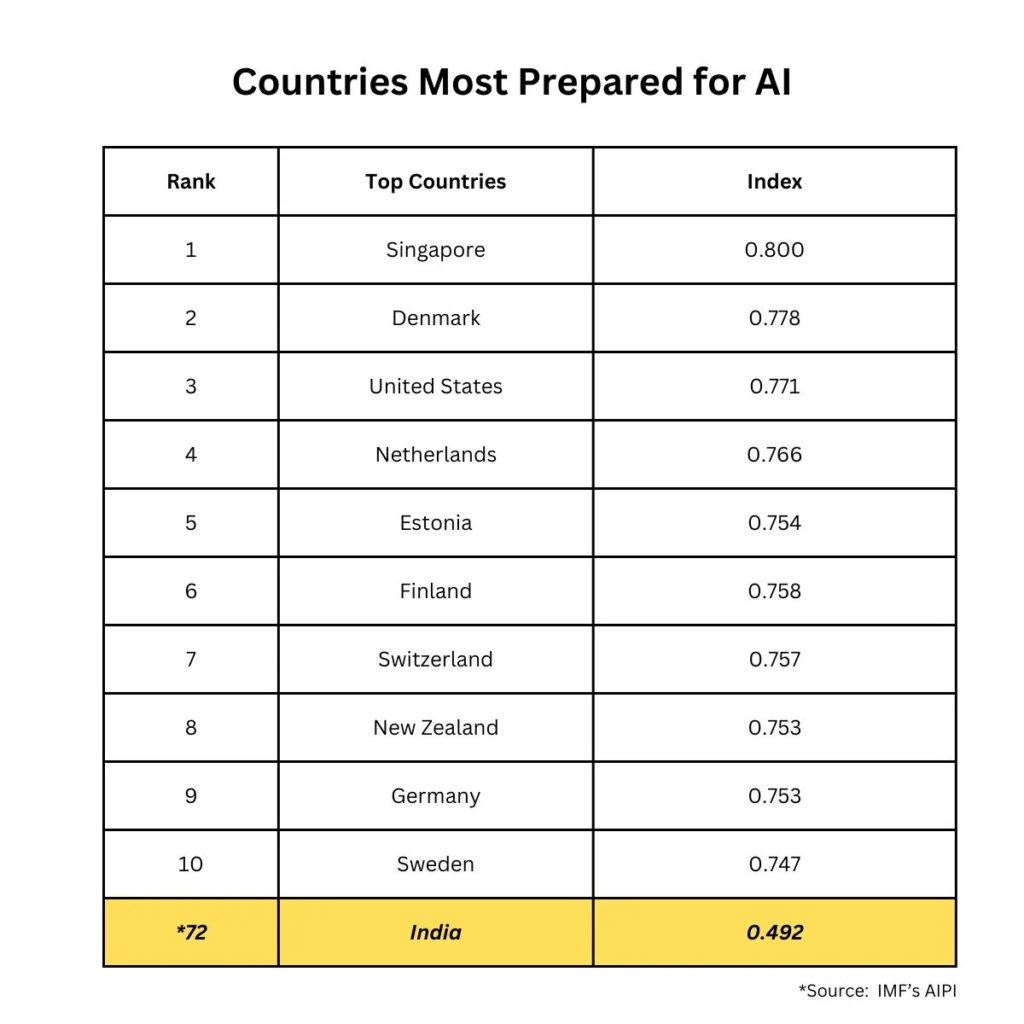
LLM and AI Agents: Solution Architecture Considerations
2025 and beyond are considered the era of AI LLM agents. There is lot of buzz in the tech world related to LLM (Large Language Model) agents. Investments in agent frameworks and agents is skyrocketing. The hype is building day by day now. Agents can do magical things. We are very close to AGI (Artificial General Intelligence). Etc.
LLMs are not as great and intelligent as advertised. For many applications, simple prompt is not enough. Couple of layers of software and intelligent management of prompt is needed. Agent fits in this space. Architectural considerations of using agents in larger application need thorough understanding and careful implementation. Only then, the magical intelligence will happen.
It is high time to look at this whole topic from overall system perspective. There are many articles going into specific low-level details of LLMs. But I have not seen any attempt to look at all layers of solution and bring them together.
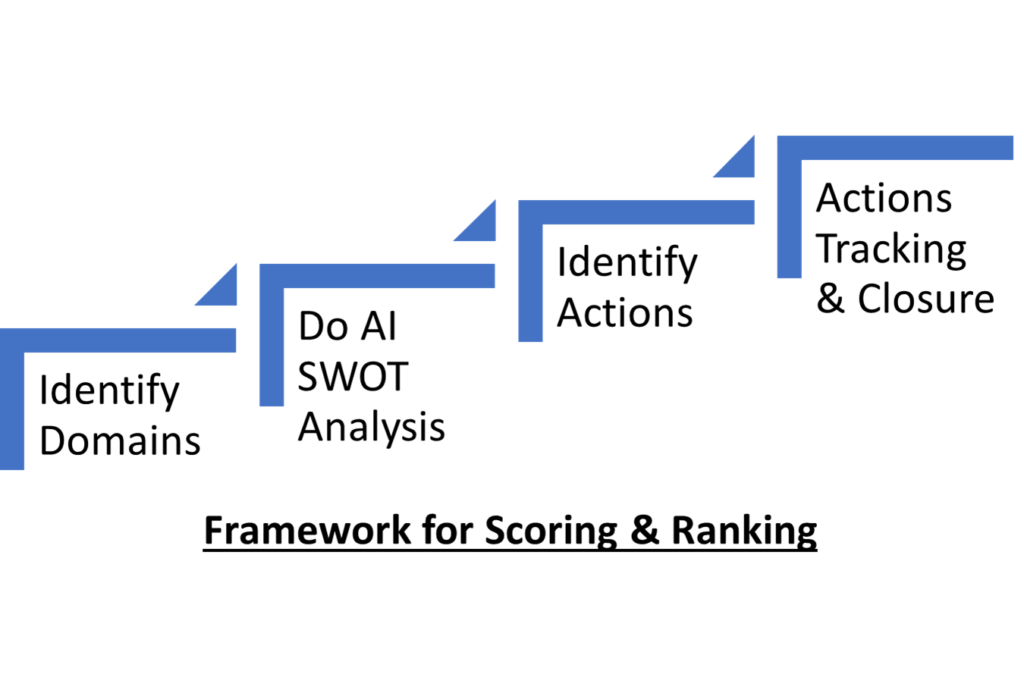
That is exactly what I will do in this post. We will examine the following :
- LLM’s ML Model
- LLM with API
- LLM Agent Layer
- Overall Application
After brief review, we will put these together and understand the solution considerations.
Let us start with LLM’s ML model
LLM ML Model
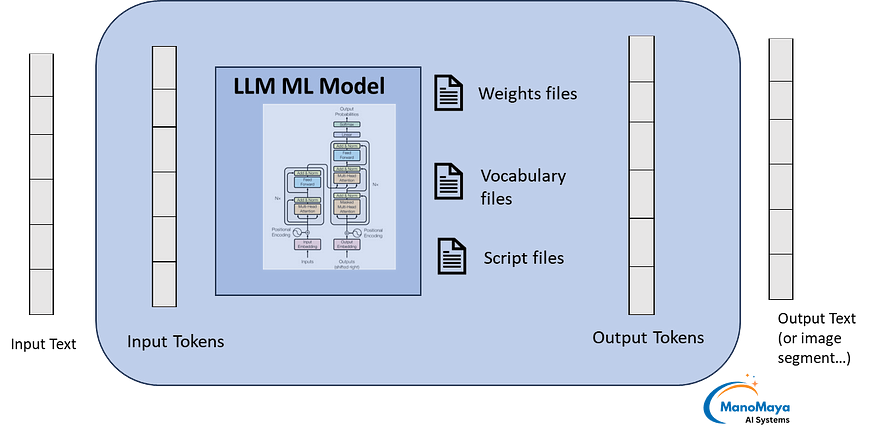
LLMs are just “next-word-prediction” ML models. Since they memorized lot of vocabulary and context, they can predict the most appropriate token sequences. These tokens are decoded to give the output text.
In large language models (LLMs), a token is essentially a chunk of text that the model processes as a unit. Tokens can be whole words, sub-words, or even single characters, depending on the model’s tokenizer and language. When you input text into an LLM, the model breaks it down into these tokens to analyze and generate responses.
In this post, we will not get into model architecture. There are many articles online on Transformer and other architectural element. We will focus on deployment and design perspectives.
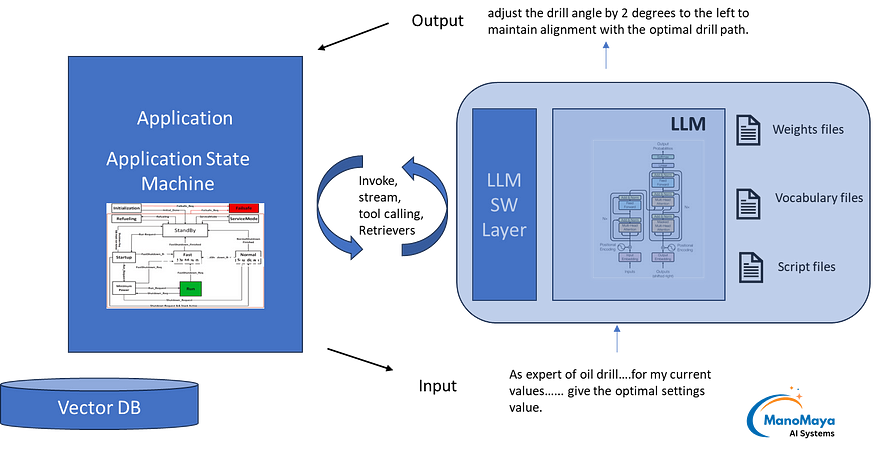
From deployment perspective, the ML model would consist of files like these:
- Weights: pytorch_model.bin, model_weights.ckpt
- Vocabulary: vocab.txt, merges.txt, tokenizer.json
- Software Layer: config.json, generation_config.json, run_inference.py
As we know, the output text is generally good if prompt contains right context and clear instructions. It is also well known that output may not be good enough the first time.
If human is directly interacting with model, he can evaluate the response and alter prompt. The quality of output depends upon how well the user is applying mind and domain expertise. So he must refine the prompt based on latest response to get the best answer.
When applications interface with the LLMs and provide a service to end users, they need to bring their unique strength. These could be domain expertise, evaluation expertise, decisions on whether to refine prompt & get better response etc. Applications may also need to decide whether to rely on external world such as inhouse DB or internet to give refined prompts. In other terms, applications should mimic how a human will do the prompting.
Hence logic external to LLM’s model is very much necessary for real world applications where expert human is not directly doing the prompt.
The artificial intelligence comes by evaluating the output of ML model, evaluating against real world needs and refined prompting based on that.
LLM with API
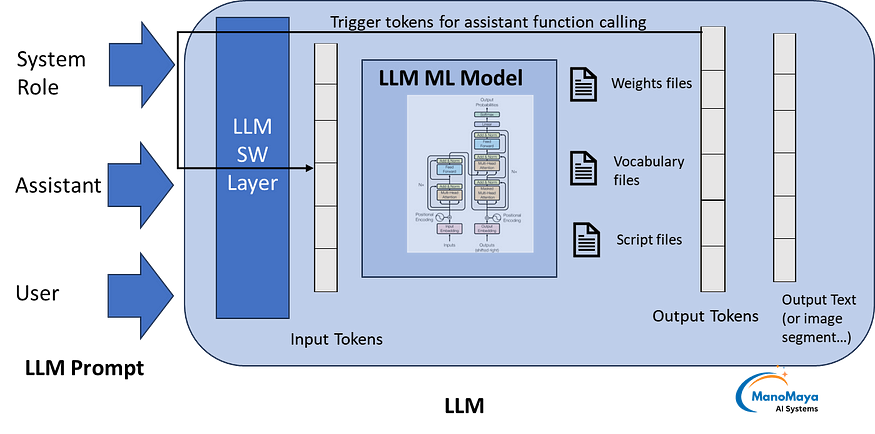
From the programming interface perspective, LLMs would provide a package and API. The LLMs released since 2024 are more sophisticated compared to older ones. They have larger context window. Instead of just one input text field, they provide 3 parameters at least.
- System role
- Assistant/Agent role
- User prompt
All of these together form the input text.
System role is kept in the beginning of the final prompt to LLM. It always gives the overall context. Hence it is always part of the prompt, if there are multiple prompts during the agent execution.
Assistant is used for passing text related to agent functionality and agent response. Depending upon the intent, some part of this may be retained or altered by the LLM client that is implementing the agent. This also has function passed to the LLM’s API for calling from LLM API if needed. The ‘function calling’ is a feature to let LLM get external information through a function call from the API software layer. It may be triggered by ‘trigger tokens’ in the output tokens generated by LLM. The software layer checks the output tokens for trigger criteria to call function passed by the assistant parameter. The function call helps in ‘guided generation’. One of the use case is ‘output format’. Ensuring JSON format of the output. You can find more on the application examples are in upcoming sections.
User prompt is the part that may change with every prompt.
All of the above create the final prompt for LLM while LLM itself is just a normal ML model which does not know about the agents, system role etc.
LLM Agent Layer
Now comes the agent
There are many tech companies separately funded to make powerful and intelligent agents.

Even with software layer enhancements of LLMs, still a lot cannot be achieved through one or two prompts. It needs more sophisticated work breakdown, evaluation of prompt & rewriting the user prompt if necessary. Also, it is needed to evaluate response and prompt again with refinement. Also retrieve relevant information from external sources. Depending upon response from LLMs and from external world, they need to take different decisions.
All of these are complex. To meet the product requirement, it needs a state machine just to manage LLM & related AI.
Thus, LLM agent has lot of work to do.
- Retrieving: Retrieving relevant data from Vector DB to be provided within the prompt. In RAG applications, the context may have many documents with too many pages. Everything can not fit within the prompt. The retrievers might be needed to intelligently filter the relevant part.
- LLM prompting: Since agent comes in when complex tasks with high expectations, the prompt may be dynamically created and run. Also main objective could be broken down to smaller prompts.
- LLM function calling: The concept of function calling is explained earlier. The functions may be web search or other tasks to be called from within software layer of LLM. Agent can do a function call itself or facilitate passing the function to LLM’s API.
- External tasks to be done at the level of agent. These could be web search, DB queries or REST API calls and many more.
Using the above functionality, very smart agents can be built. Here is an example from IoT and smart campuses domain.
Example Agent — Requirements: Smart Building Air Quality Agent
Smart buildings air quality sensor IoT device: It needs to enhance the sensor information with local weather information, translate it to another language, double check the overall message and then send to remote operator. In addition, the local node also needs to read big maintenance document, ensure that the sensor values don’t fall outside realistic range. If so, it also needs to add maintenance alert.
In the above, ‘Air quality sensor IoT’ device needs to do many things. Invoking LLM, passing a function to LLM for verifying language translation, doing web search, accessing a large maintenance document & answering from that etc.
Design of Agent — Concept Summary:
Before we continue with the example agent, we need to understand few concepts. To design an agent, the agent libraries provide lot of support. Some of these provide agent frameworks, vector DB and other pieces outside LLMs.
To create the agent, the agent framework provide GUI based tools too.
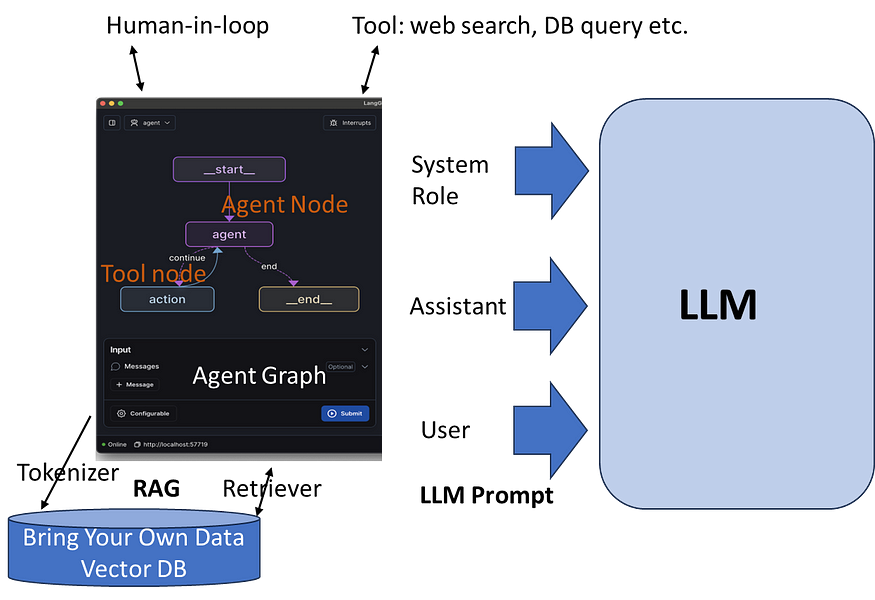
For example, LangChain provides this graph definition and execution ability. There is visual assistance to create the graph (state machine that governs the agent behaviour) and to run and debug the agents.
In this graph
- Node: Each node represents agent action. The node represents a python function that carries out the main work of the node.
- Edge : Edge connects the nodes. It is a python function through which control goes from one to another. Main job of edge function is to do the job of connecting nodes. i.e. it has the logic to decide which node needs to be executed next.
- State : State is the object passed between nodes. The content of state depends upon the design of the graph. It could have LLM output, intermediate results, incremental result etc. The contents depend upon the way Graph is designed.
The work outlined in previous section such as LLM function calling, web search and others would go into nodes and edges.
The most important work to be done in the workflow should be in the nodes. The edges can also do some work if it is relevant for the edge. Mainly it depends upon the conceptual design of the graphs and the nodes of the agent.
The nodes could be of different types.
- Main data processing task doing LLM prompt
- Tool node querying external source or
- Retriever retrieving relevant data from a vector DB.
Different libraries provide node type classes for these.
The agent would interface with LLM through the published APIs. From 2024, most LLMs provide large context window and separate parameters for system role, assistant and user roles.
With older models, the agent frameworks managed these within themselves and sent the combined prompt to LLM.
AI is only one part of the story. What happens to overall application integration?
Example Agent — Design of Smart Building Air Quality Agent
In previous sections we saw the concepts of agent nodes and edges. Here we do a rough design of agent. First, a high level summary of a crude work flow. Second, identify few nodes. Third, agent edges. We are not generating graph here. LangGraph requires paid component LangSmith. Hence we just stop at listing the graph details. Also the main goal of this article is not to illustrate the agent design specifics. But to bring out the solution considerations of the framework.
Smart Building Air Quality Agent : Workflow steps
- Sensor reports air quality levels as below acceptance level. It gives levels of CO2, particles in air etc.
- Maintenance step checks the levels of various levels like CO2 against thresholds in the sensor maintenance document. This is to ensure that sensor is not doing false alarm due to clogged filters or other sensor parts.
- Weather node retrieves humidity, temperature, traffic conditions etc. This helps as auxiliary information to confirm the findings of sensor.
- Combined data is flagged for a possible air quality issue. (Sensor fusion step). Alert is generated if thresholds are breached. At this step language translation is done through LLM prompt.
- Verified alert message is sent to the operator. (Human in loop)
- Based on human operator confirmation, it is sent to larger set of recipients.
Smart Building Air Quality Sensor : Agent Graph Nodes
- #1Primary Sensor Node : Main sensor that detects multiple elements of air quality. Input: Sensor readings (CO2, particles in air etc.). Output: Structured sensor data. Tools Used: Preprocessing functions to validate raw data and normalize for processing.
- #2 Maintenance check node: Input: Sensor input. Output: Maintenance specific readings such as filter dirty level. Also gives its own ‘plausibility level’ considering the sensor readings and maintenance related readings. Tools Used: Reading local maintenance features.
- #3 Weather Information Node : Input: Location coordinates from local sensor. Output: Current local weather information (e.g., temperature, humidity, traffic). Tools Used: External API call for weather data retrieval.
- #4 Sensor Fusion Node : Input: Inputs from both Primary sensor node and Weather information node. Output: Confirmed air quality output with explanation of supporting data . Tools Used: External API call for weather data retrieval.
- #5 Translation Node : Input: Output of sensor fusion. Output: Overall air quality alert with human operator confirmation. Tools Used: HMI Human Machine Interface, integration such as REST API to send/receive alert data.
- #6 Human Confirmation Node : Input: Output of sensor fusion. Output: Overall air quality alert with human operator confirmation. Tools Used: HMI Human Machine Interface, integration such as REST API to send/receive alert data.
- #7 Alert Broadcast Node : Input: Operator approved alert. Output: Confirmation of broadcast to intended recipients. Tools Used: Broadcast APIs
Smart Building Air Quality Sensor : Agent Graph Edges
In the above graph, the primary sensor is connected to maintenance node through unconditional edge function. Likewise there is edge from maintenance node to weather info node. A conditional edge from #1 primary sensor, #2 maintenance and #3 weather info node will take to further nodes. These are sequentially connected.
The final step loops back to node #1, indicating continuous operation.
The above is the high level design of what an agent can do and how it can be approached. This example is inspired by the air quality issue faced by Delhi and rest of “Indo-Gangetic area” in Indian subcontinent.
Example Agent Design — Key Takeaways :
Main point is that agent design has lot of consideration for the overall application. It certainly has multiple prompts and quality check etc (not shown in above design). But there is huge consideration for overall functionality and external world interaction.
Hence the overall application considerations are a big part of agent design.
Overall Application
Remember that the overall solution is overall goal and commitment to the end user. It may have its own functionality and state machine. This brings up multiple ways of integration with LLMs.
Integration Option: Have dedicated Agent layer
One integration option is to follow the current trend. For AI agent, use the framework. Integrate the application with appropriate integration as per application needs. These could be REST API, local direct calls or other integration options of software layers.
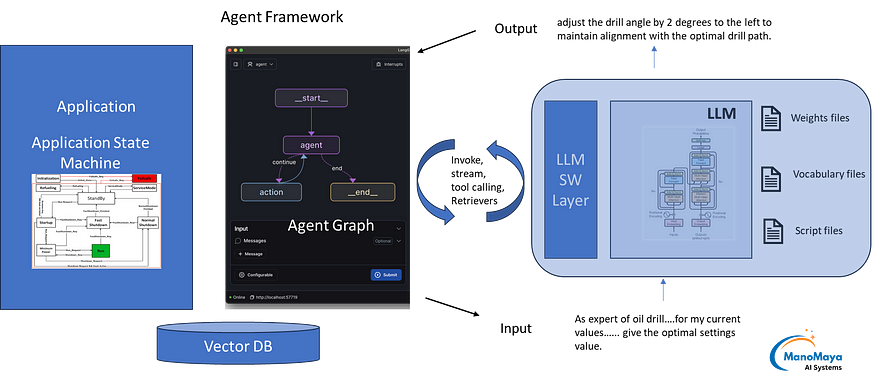
Integration Option : Direction Integration without any Agent Framework
The second is to directly interface with LLM API. Just integrate with the LLM APIs and packages.
Considerations for using agent framework.
From what we explored so far, the following are the pros and cons of using agent framework, as opposed to directly integrating LLM’s API.
Pros – Using agent framework instead of merging the functionality directly into overall solution:
- Decouples LLM and AI from rest of the application. Helps to do better talent management. Makes switching across LLMs easier.
- Agent infrastructure improves productivity
- LLM agent state machine would be pretty similar to other agents. Implementing agent functionality directly in application may end up complicating the application. The application state machine could become overly complicated and hard to maintain.
Cons – :
- While making agent framework generic, the design is likely to involve more tokens. This directly increases cost.
- Some frameworks are ‘sticky’. They end up dragging the entire application to expensive cloud hosting. If there is no clear path to revenue, ensure that there is enough cost runway for the project.
- In some cases, agent framework may be an overkill. The functionality to be achieved could be accommodated within main application state machine. If the application is ok to directly interface with LLM’s API, it can work for many cases.
It is rapidly evolving area. Framework keeps getting updated every few days. It is better to be constantly monitoring the releases and changes.
Wrapping it up,
Overall, AI agents bring lot of opportunities to innovate. Some solutions were never possible before. They are now possible. AI agent is here to stay.